以前写博客,从来没坚持过一年,这次出乎意料的做到了新建了一个2024的文件夹了。希望之后还能继续。
新年第一篇,这周其实过得不怎么好,最近的运势似乎并不站在我这边。跨年那晚在油管看台湾的跨年,陈绮贞唱了半个多小时,台湾人民吃得还是好,大陆南方网友表示嫉妒。
从豆瓣到Notion
2020年在家隔离的时候,那时候也没上班,就看了蛮多书的。当时用notion搭了个读书的数据库,个人感觉成就感满满,之后开始上班就没怎么维护了。最近逛别人博客的时候发现好多人都有在用notion做自己的数据库,我就想起了我当时建的这个数据库,正好我一直想要一个「书影游」的数据库,正好来搭建一下。
当时都是纯手工一条条录的,要是想搭建一个比较完整的「书影游」,我这个数据量应该挺大的(其实不大)。网上搜了搜,虽然有不少「逃离豆瓣」的攻略,比如很多博主推荐的豆瓣读书+电影+音乐+游戏+舞台剧导出工具我这边打开是404的状态(估计被警告了),NeoDB推荐的豆伴(豆坟)倒是还算好用,不过我看到有博主说豆坟有可能导致封号,问题不大(人生就是一场豪赌)。
其实我中间踩了坑绕了几个弯路,最开始的思路是把从豆瓣导出的.xlsx数据转成csv格式,如果想要已读、想读、已看、想看之类的功能,手动修改一下豆伴导出的文件就可以了。然后把导出的csv文件直接导入到notion里,其实要说这一步就能满足大部分的需求了。
但是我想要封面!因为导出的文件里有豆瓣链接,最开始是想用python直接去爬豆瓣的图,一开始倒是都好好的,爬了一百来张就触发了反爬机制,也懒得去研究反爬了。
重点来啦,这里要着重点赞豆瓣的平替neodb,前面导出的时候也说了嘛,导出后就可以导入到这里面来。与豆瓣不同的是,这是个开放的平台,它能调用api!
当你导入了豆瓣的数据后,我又导出了一份NeoDB的备份。参照他们的Developer Console把所有的书影都爬了一遍。
import requests
import json
import pandas as pd
import time
df = pd.read_csv("movie.csv")
df['NeoDB链接']=df['NeoDB链接'].astype(str)
header={'Authorization':'Bearer xhUlIQDgfb11mokXBsZAmjvwO5r2Qm',}#这里的Token就直接在上面的链接拿一个Test Access Token就是了,不知道为什么我按它写的注册应用程序没用,拿不到。反正几千个数据一会就爬完了。
for x,i in enumerate(df['NeoDB链接']):
url = i
content = url.split('https://neodb.social/')[1]
print(content)
response = requests.get('https://neodb.social/api/'+content,headers=header)
data=json.loads(response.text)
df.loc[df['NeoDB链接'] == i, '封面'] = data['cover_image_url']
df.loc[df['NeoDB链接'] == i, 'type'] = data['type']
df.loc[df['NeoDB链接'] == i, 'brief'] = data['brief']
actors = ','.join(data['actor'])
df.loc[df['NeoDB链接'] == i, '演员'] = actors
genre = ','.join(data['genre'])
df.loc[df['NeoDB链接'] == i, '类型'] = genre
df.loc[df['NeoDB链接'] == i, '年份'] = data['year']
area=','.join(data['area'])
df.loc[df['NeoDB链接'] == i, '地区'] = area
df.loc[df['NeoDB链接'] == i, 'NeoDB评分'] = data['rating']
print(f'正在处理{x + 1},共{len(df)}')
time.sleep(0.5)
df.to_csv('NeoDB备份.csv',index=False)
不是程序员,所以代码也不知道写得好不好,反正能用,能用就行。把导出的csv导入到notion,改改属性就非常完美了。
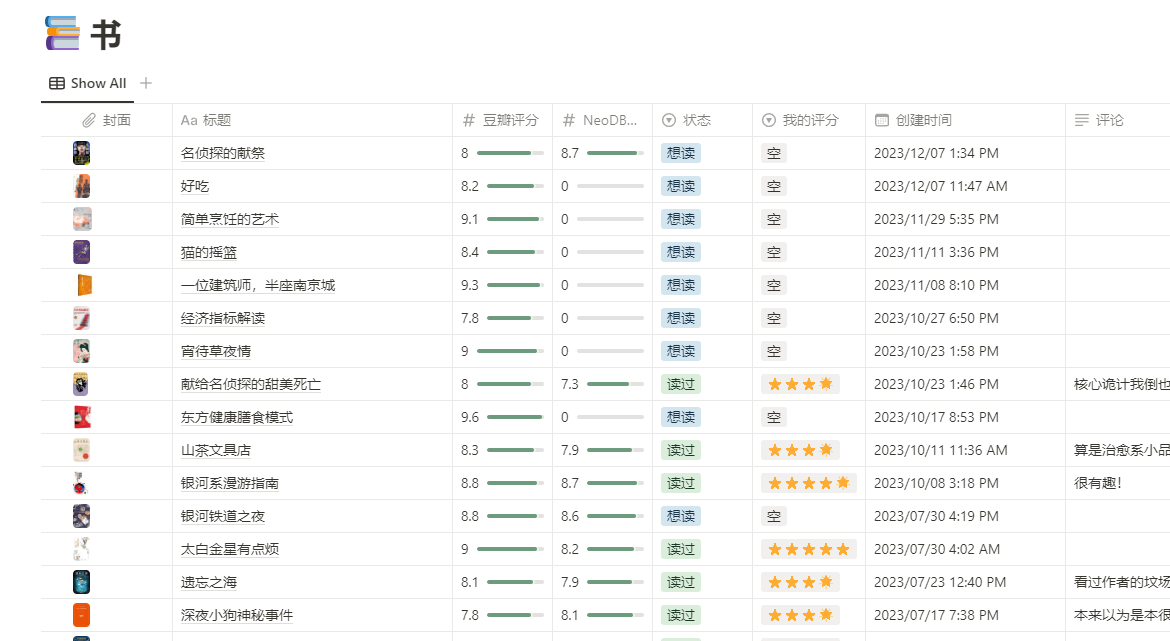
据说notion是可以当数据库用的,想想它的可能性,很酷。
TO DO
- 现在虽然搭建好了,接下来就是看看如何实现在一个网站标记,三个网站同时更新(毕竟我也不是说不用豆瓣了)。
- 「游」板块目前空缺。
- 写代码有点快乐,想继续写点别的有的没的。
感觉有趣的东西

怪物猎人·世界
太刀虽然帅,但是太容易猫了,瓶颈了一个礼拜了。肝了好久的咩咩子,做出来的太刀感觉不咋好用…..准备换一把,古龙不能捕获简直就是逼肝。网上都说好看的衣服都在冰原,可是钢龙我打了好几个小时才过,打完钢龙老师学会了见切(明明之前拜年剑法就很好用),现在已经是见切大回旋登龙接猫车一条龙,猫的明明白白。
以及在苍蓝星到处抓仙人掌,隔壁艾欧泽亚的仙人掌都是拉拉肥扮演的,四舍五入我抓了一房子拉拉肥。
这周没啥特别好记录的东西,空气也不好心情也不好。